Since 2023, administrators have been able to enable Optical Character Recognition (OCR) for files stored in SharePoint Site Collections.
OCR can extract handwritten text or text in images from many file types and prepare it as readable text. Since last October, OCR also supports images in PDF files. The text can be used by products such as Microsoft Purview or Microsoft 365 search.
Microsoft has extended OCR to files in OneDrive.
OCR is a SharePoint Premium Feature. Like everything with SharePoint Premium, it is billed through Syntex Pay-as-you-go (PAYG).
As with all SharePoint Premium features, I test the feature in practice. I am using the extension to OneDrive for my practical OCR test. Generally, OCR is not a new SharePoint Premium feature.
Content
Configuring Optical Character Recognition
Set up Syntex Pay-as-you-go
As usual, SharePoint Premium features require the one-time configuration of Syntex pay-as-you-go (PAYG). SharePoint Premium bills all its monthly costs through the Azure Subscription. You can skip this step if Syntex pay-as-you-go has been set up in the past for other SharePoint Premium features.
Enable Optical Character Recognition
An account with the role of SharePoint Administrator or Global Administrator must activate OCR in the Microsoft 365 Admin Center.
Open the M365 Admin Center > Org settings > Pay-as-you-go services > Settings > Optical Character Recognition.
You will find a new section for OneDrive in addition to enabling SharePoint Site Collections. The OCR service can be independently enabled or disabled for both SharePoint and OneDrive. Compared to SharePoint Site Collections, you select user accounts or user groups for OneDrive.
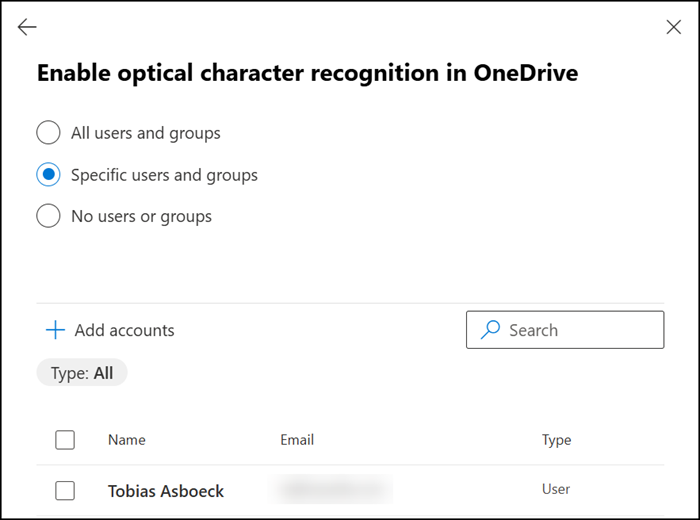
The activation requires no further steps. Within a few minutes, OCR is enabled for OneDrive accounts and SharePoint Site Collections.
Using Optical Character Recognition
SharePoint Premium will begin extracting text from images and supported files after the configuration. Neither the administrator nor the user has any option on which files are processed. OCR analyzes all supported file types in the defined OneDrive and SharePoint Site Collections. Additionally, as is known from other SharePoint Premium features, OCR cannot be manually started per file.
- All newly uploaded or modified files will be analyzed by OCR. Each modification restarts the OCR process.
- Existing files may remain unprocessed by OCR. In that case, it may help to either re-upload the file or modify it once.
- If OCR cannot extract text, you are out of luck. Neither users nor administrators can change the process. It is like with all SharePoint Premium features; it works or it doesn’t. Microsoft Support will refer to the documentation. #Blackbox
You should note the limits:
- Images must be less than 50 MB.
- Images must be at least 50 x 50 pixels and not larger than 16,000 x 16,000 pixels.
- Images uploaded after OCR has been enabled are the only images that are scanned.
- Images that are embedded in Office documents aren’t supported.
OCR in SharePoint Site Collections
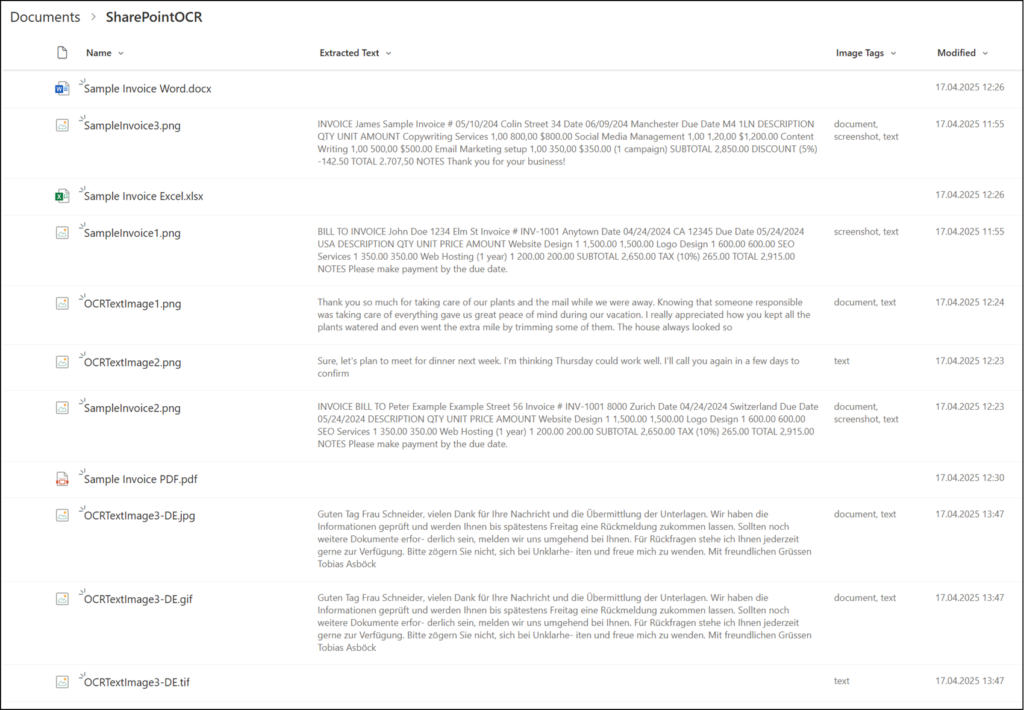
OCR extracts the text into the column “Extracted Text”. You should add the column to your document library for verification. Microsoft notes that not all data is stored in the column.
When you apply OCR to an image file, the text is stored in the Extracted text metadata column. When you apply OCR to a PDF or TIFF file, the extracted text is indexed in search but not available in the metadata column.
ChatGPT created some examples for me: images and files with invoices + other text
OCR extracted the text within a minute in a SharePoint Site Collection, and it was able to extract the text in many cases. In my Word and Excel files, there is only text, no images. OCR only extracts text from images in Office files. Text from Office files is already indexed with Microsoft 365 search. The text in “Extracted Text” is now also in the search index and can be used with Microsoft Purview.
OCR in OneDrive for Business
With OCR in OneDrive, it is clear that a different team developed the extension. They did not review the implementation after the development was completed, or they had no practical experience, or it was just a task to complete. From my view, they got the task of extending OCR to OneDrive, nothing more. They completed just that task.
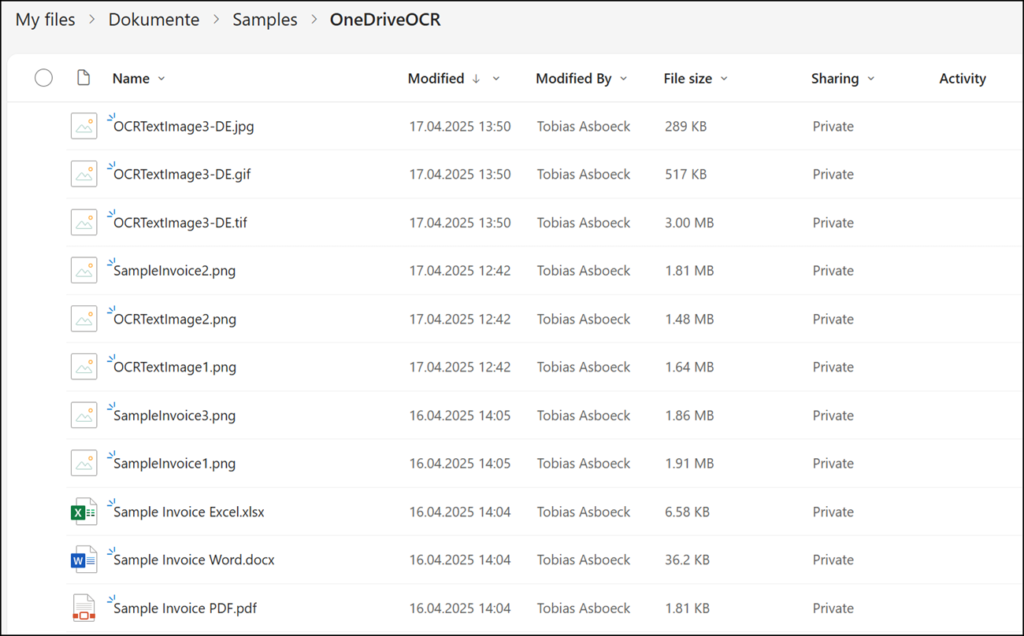
- The team forgot that a document library’s view and capabilities in OneDrive differ from those in SharePoint Site Collections.
- The team forgot to display the extracted text in OneDrive. Unlike a SharePoint document library, users cannot manually add a column in OneDrive.
- The OCR process needs 24 hours for text extraction in OneDrive. In comparison, the process is done within a minute in SharePoint.
This is what a OneDrive library looks like in the default configuration with OCR. Information from OCR is missing and cannot be added.
As a SharePoint admin, I know how to add the information via SharePoint Classic. OneDrive still includes the SharePoint Classic mode.
You cannot change the predefined default view from Microsoft in the OneDrive document library, but you can create a new view. I manually created a new view and modified the columns. Microsoft uses the internal column name for OCR in a OneDrive library: MediaServiceOCR (instead of the “Extracted Text” column)
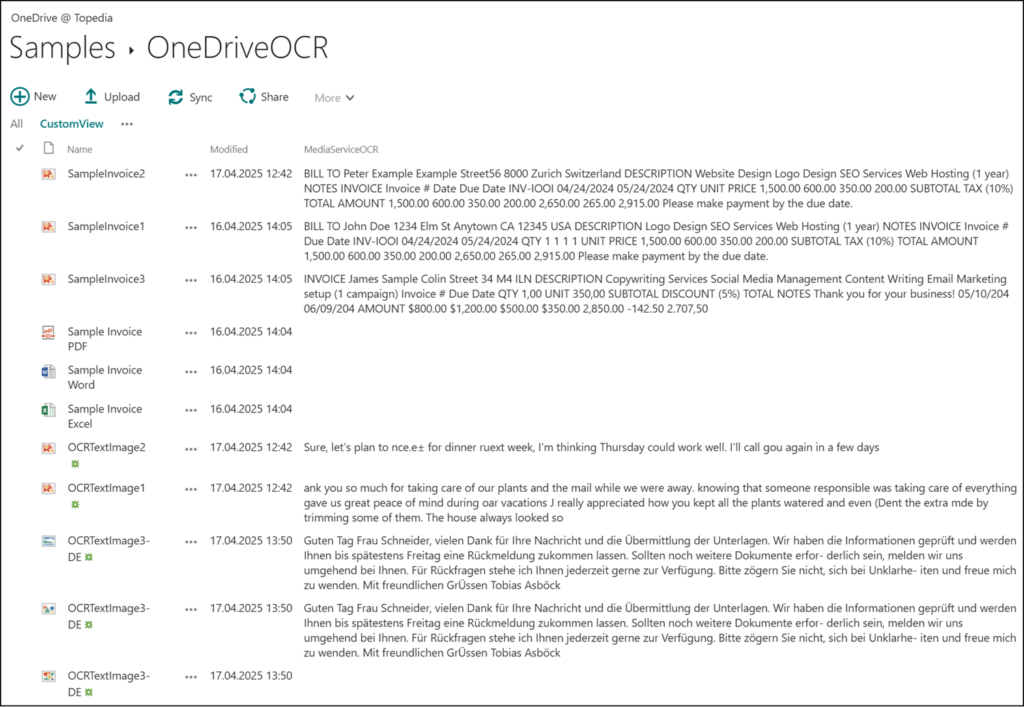
The extracted text is included in the MediaServiceOCR column after 24 hours. At least a test is possible to see if OCR works in OneDrive with SharePoint Classic.
I don’t recommend the productive use of OCR in OneDrive at the current development stage. As always, everything about SharePoint Premium is very intransparent and a black box.
Costs of Optical Character Recognition
OCR in SharePoint and OneDrive is billed per analyzed page; each page is a transaction, with every edit.
Optical Character Recognition
- The number of pages processed for images (JPEG, JPG, PNG, or BMP)
- the number of pages processed for PDF, TIF, or TIFF
- or the number of embedded images in Teams chats and email messages.
- Each of these counts as one transaction. Processing occurs every time the file is edited.
- $0.001/transaction
How to get a cost report
Microsoft still does not provide a customer-friendly report for Syntex PAYG in Azure.

You can get the cost and usage report with my analysis from January.
# Get the PAYG costs from an Azure subscription
# PowerShell module Az.Billing is required: https://www.powershellgallery.com/packages/Az.Billing
Import-Module Az.Accounts, Az.Billing
# Define the Azure subscription ID and the resource group name
$AzureSubscriptionID = "<AzureSubscriptionID>"
$ResourceGroupName = "<ResourceGroupName>"
# Use an account or service principal with at least the Cost Management Reader role to connect
Connect-AzAccount -SubscriptionId $AzureSubscriptionID
# Define the current month as the time period for the cost report
$CurrentDate = Get-Date
$StartDate = (Get-Date -Year $CurrentDate.Year -Month $CurrentDate.Month -Day 1).ToString("yyyy-MM-dd")
$EndDate = Get-Date -format "yyyy-MM-dd"
# Get the cost details for the specified resource group and time period
$CostDetails = Get-AzConsumptionUsageDetail -ResourceGroup $ResourceGroupName -StartDate $StartDate -EndDate $EndDate -IncludeMeterDetails -IncludeAdditionalProperties -Expand MeterDetails
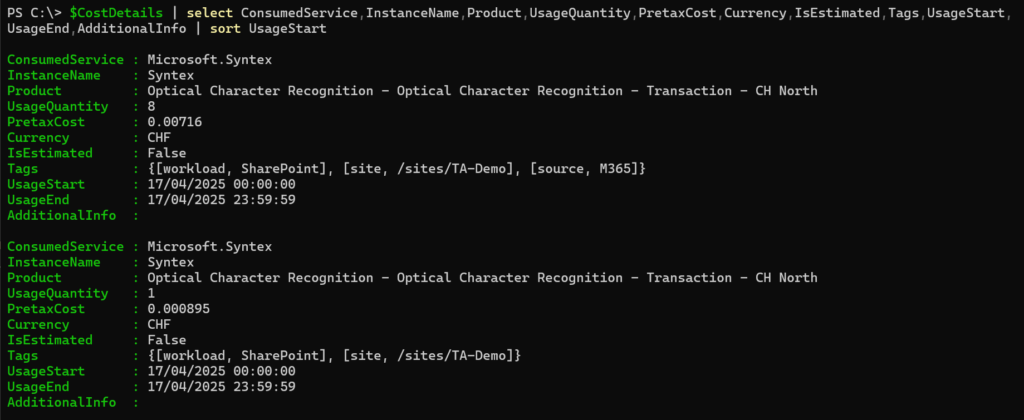
$CostDetails | select ConsumedService,InstanceName,Product,UsageQuantity,PretaxCost,Currency,IsEstimated,Tags,UsageStart,UsageEnd,AdditionalInfo | sort UsageStart
The result includes the date, consumption, and which Site Collection. OneDrive is missing in the report, as OCR processed the content on 18 April.