In November 2024, Microsoft announced a new Syntex prebuilt model for SharePoint Premium: Simple document
The simple document processing model offers a flexible, pretrained solution for extracting key-value pairs, selection marks, and named entities from basic structured documents. Unlike other prebuilt models with fixed schemas, this model can identify keys that others might miss, providing a valuable alternative to custom model labeling and training. This model also supports barcodes and language detection.
The new model should be already available.
Microsoft now provides five prebuilt models:
- Contracts
- Invoices
- Receipts
- Sensitive information
- Simple documents
These models can be useful for organizations because Syntex prepares the extracted information for other products (such as Microsoft Purview, Power Automate, Microsoft Search, and others) for following tasks and stores it as readable metadata.
Simple documents currently supports formats such as .bmp, .jpeg, .pdf, .png, and .tiff, with more formats to follow.
With the model, SharePoint can automatically extract general information from supported files using OCR (Optical character recognition) and store the information as metadata in a SharePoint document library. The model can also identify the language in which a document was created (up to 100 languages). Read the limitations of the simple document model.
The simple documents model can extract the following information from documents:
- Key-value pairs – Think of these like labels and their corresponding information, such as “Name: Adele Vance.”
- Selection marks – These are checkboxes or other marks that indicate choices or selections in a document.
- Named entities – These are specific items like names of people, places, or organizations mentioned in the text of a document.
- Barcodes – These are machine-readable representations of data that can be used for tracking or identification purposes in a document.
I tested the new model.
Note, all sample documents and data were randomly generated by ChatGPT and exported in three languages.
Content
If you have already set up the steps for configuring prebuilt models for Syntex in the past, you can skip them and continue with the model creation.
Configuration of prebuilt models in SharePoint
1) Syntex pay-as-you-go
To access Syntex and SharePoint Premium features, you first need to complete a one-time configuration of Syntex pay-as-you-go. All monthly costs for SharePoint Premium are billed through your Azure subscription. If you have already set up Syntex pay-as-you-go for other SharePoint Premium features in the past, you can skip this step.
2) SharePoint Content Center
A Content Center is necessary for prebuilt models. Model creation and training at the organizational level occur in the Content Center, which is a SharePoint Site Collection predefined by Microsoft.
- Enterprise Content Center
The Enterprise Content Center is an organization-wide content center. In an Enterprise Content Center, authorized accounts create and train the models predefined by Microsoft centrally and assign the models to SharePoint document libraries. SharePoint later publishes the models, which are updated here in the linked document libraries. - Local Content Center
A local Content Center is connected to a defined site collection. Models are only available for document libraries in this site collection.
Microsoft describes the creation of a content center.
SharePoint administrators can create one or more content centers, but there can only be one standard content center. Syntex defines the first Content Center as a standard Content Center. The first Content Center should be an Enterprise Content Center.
3) Activate prebuilt models
In the M365 Admin Center, accounts with the Global Admin or SharePoint Admin role activate Prebuilt Models and allow the model for Site Collections. Please note that you must also enable the Content Center itself to create prebuilt models.
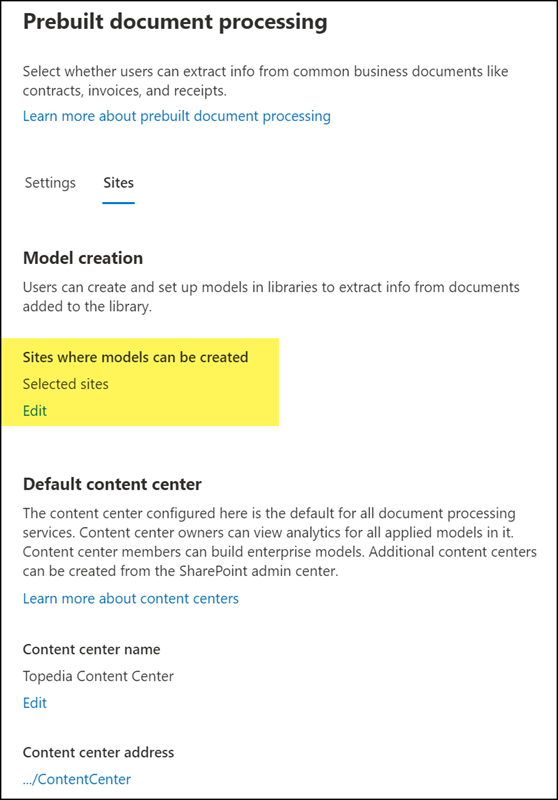
Creation and training of simple document model
1) Model creation
Open the Enterprise Content Center, create a new model in the navigation at Models, and select “Simple document processing.”
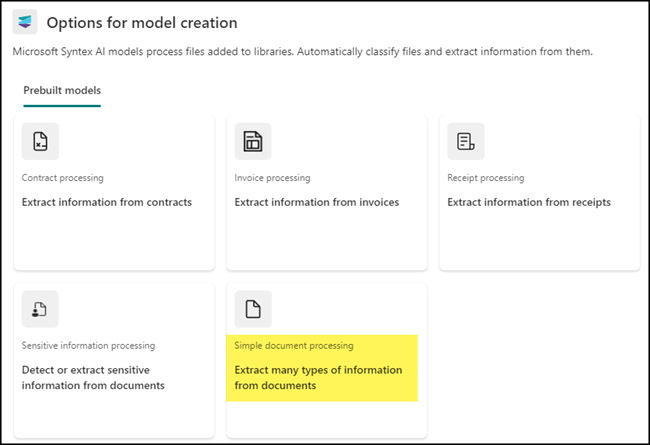
In the next step, the model informs you which information it can extract.
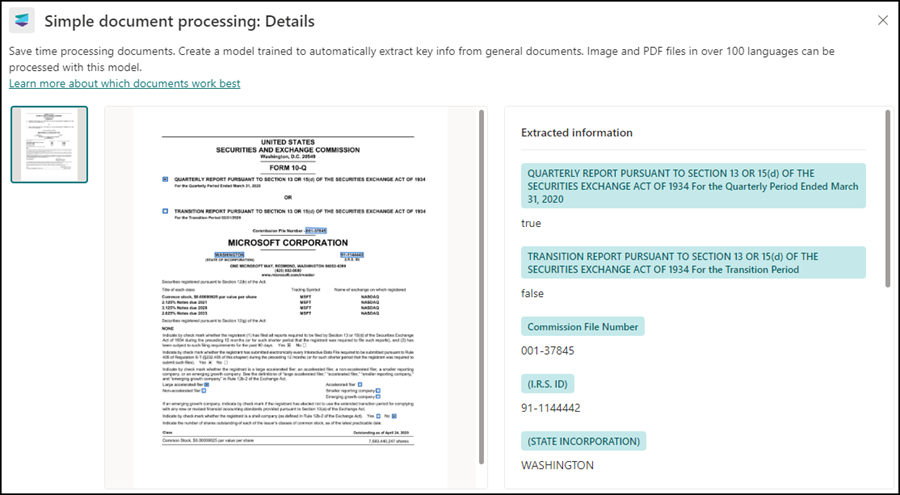
You define a name and description for the model and create the model. You can also set additional standard configurations for preconfigured content type, sensitivity, or retention labels. The model could then automatically classify data and define a retention time.
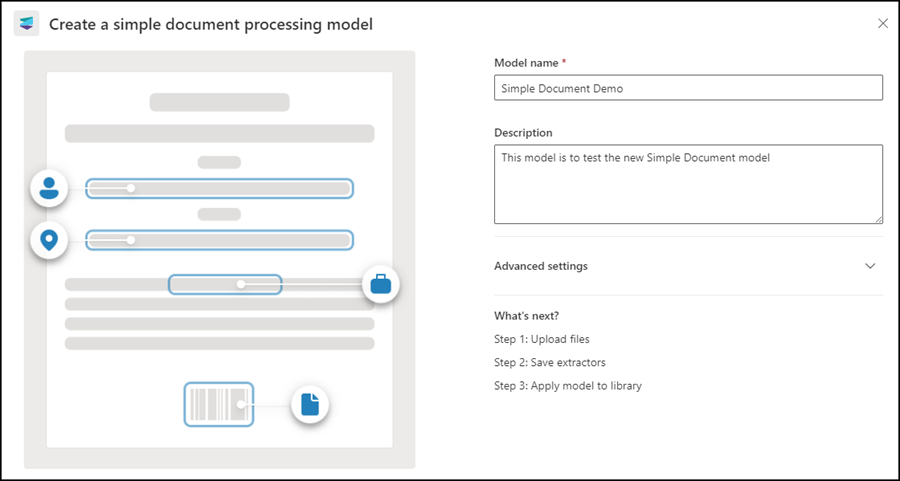
2) Model training
After the model is created, the Models Center opens with some sections. The Models Center effectively guides users through each step, and Microsoft describes all the steps.
In the Models Center, authorized persons use existing documents to train the model, define whether language recognition is active, determine which data someone wants to extract and publish the new model to selected libraries in SharePoint.
The more examples a person provides, the better SharePoint will be at recognizing the information in the future. At least five examples should be included.
Once the training is complete, the model is assigned to a SharePoint document library. This library can use the newly created model and will adapt to any future changes made to it.
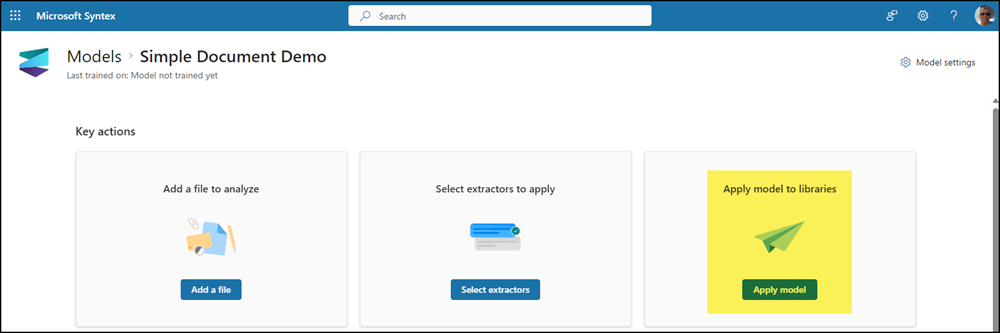
Please note that the site collection must be enabled for prebuilt models for the assignment, see the chapter how to activate prebuilt models above. Otherwise, SharePoint will inform that the site collection is not authorized to use a model.
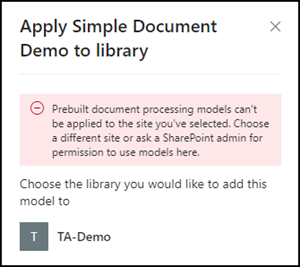
For my tests with prebuilt models, I created a new library and assigned the model to this library.
Extracting information from SharePoint documents
Once a model has been assigned to the SharePoint document library, a new option “Classify and extract” becomes available. This option indicates the models that are assigned.
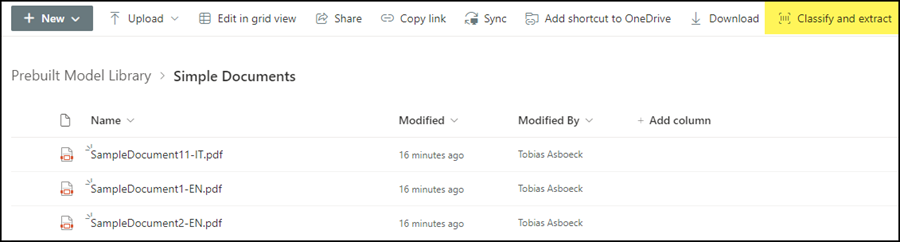
It is possible to use multiple models in one library.
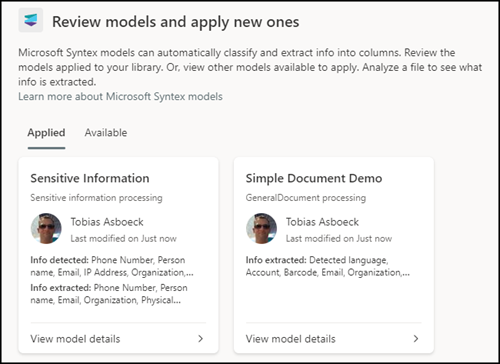
In practice, multiple models in one library are confusing and uncontrollable. Syntex informs a person has no control over the models in the library.
A model is already applied to this library. When you apply more than one, Syntex chooses how to process each file.
The assigned model applies:
- Someone must classify and extract existing documents manually. You select the desired documents and choose the option in the menu.
- SharePoint analyzes newly uploaded documents automatically.
The analysis can take up to 30 minutes. During my tests, it took less than a minute each time.
The result is a mix.
For documents in one language
It works very well. The model extracts practically all configured data.

For documents in different languages
It does not work consistently. The model only extracts some data. It can always allocate the language of the documents.
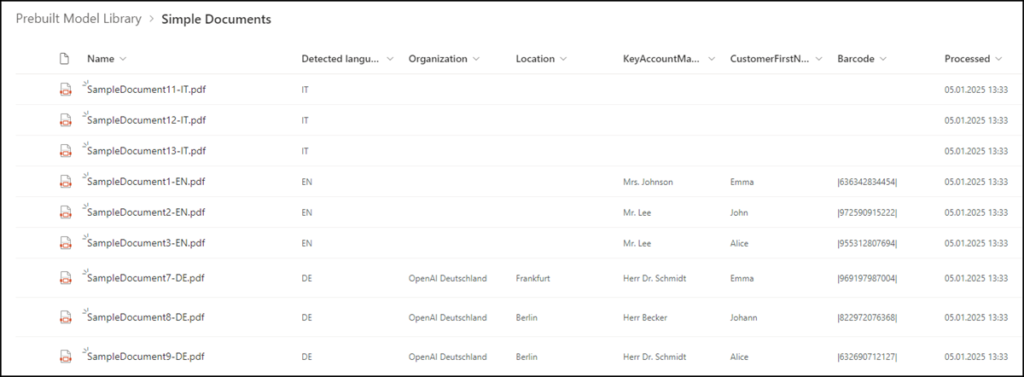
One option is to create one model per language and store documents per language in different document libraries. This allows you to assign the model to different libraries.
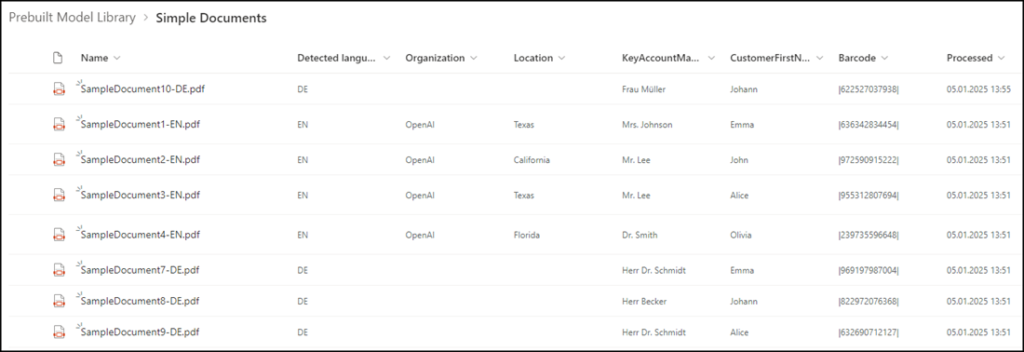
For a test, I tried both models in one library.
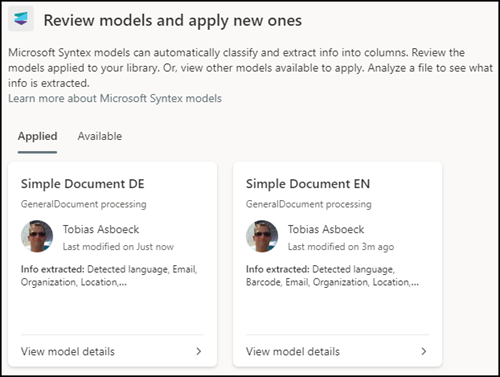
Even in this case, the result is no better for different languages.
Costs of prebuilt models in SharePoint
The creation, editing, and training of models in the Content Center are not charged. Microsoft mentions costs for prebuilt models.
$0.01/transaction
The number of pages processed for PDF or image files. Each of these counts as one transaction. You won’t be charged for model training. You’re charged for processing whether or not there’s a positive classification, or any entities extracted.Processing occurs on document upload and on subsequent updates. Processing is counted for each model applied. For example, if you have two models applied to a library and you upload or update a five-page document in that library, the total pages processed is 10.
Until June 2025, customers can test some SharePoint Premium features. For prebuilt models, the first 100 pages each month are included.
Important note on SharePoint Premium costs
Microsoft still does not provide a way to control costs for SharePoint Premium features. Once configured, all SharePoint Premium features use a single Azure subscription, and it’s impossible to set a monthly spending limit. Using SharePoint Premium can lead to significant, uncontrolled expenses. As stated in the Syntex license terms, Microsoft advises that organizations should disconnect their Azure subscription from Syntex to prevent further costs.